Fleet Commander:
Attention Is All I Need
Table of Contents
The Goal: Protecting Attention
Early in my career, the focus was on birth (deployment) of apps. Now the focus has shifted to longevity — creating a healthy ecosystem of apps.
The most important factor for a good developer is creativity and focus.
Creativity is holding a problem in your mind and really asking yourself "what is the most optimal solution?". Or put another way, "If I solve this problem will it make other problems irrelevant?" What is the strongest point of leverage?
Focus is the ability to sustain long periods of deep work. My wife calls it "holding the jenga tower in your head."

The more I invest in reducing task switching, the more productive I am. I'm not just managing code; I'm managing attention.
The Problem: The "Tedium Tax"
A fun activity would be to create a timeline of each app I have built. In a timeline, each app would illustrate the design decisions I thought were correct at the time.
At the time of writing, I have about a dozen apps actively used by my end users. The attention required to monitor each app has become a "tedium tax." Each app had its own design decisions, tech stack, ROI goals, etc. Each is a mini robot that solves a problem in my business.
As the apps scaled up, I had two choices:
- Tedium: monitor the logs daily / weekly to make sure everything is running smoothly.
- Reactive: finding out that an app broke from an end user or a system notification (usually a few days after the break takes place).
Well... if both options suck, create a new option. Or "find the strongest point of leverage."
Governance Robot or... Fleet Commander

Maybe my goal now is to build Starfleet Robotfleet. As the fleet grows, the overhead of
checking each app manually becomes a "tedium tax."
The Solution: Building More Robots
To combat the tedium I built a Fleet Commander — a logging hub. It is a lightweight docker container using FastAPI endpoints where each app can send its logs and health metrics. A 4B Gemma model monitors the overall health and, when emergencies arise, messages me.
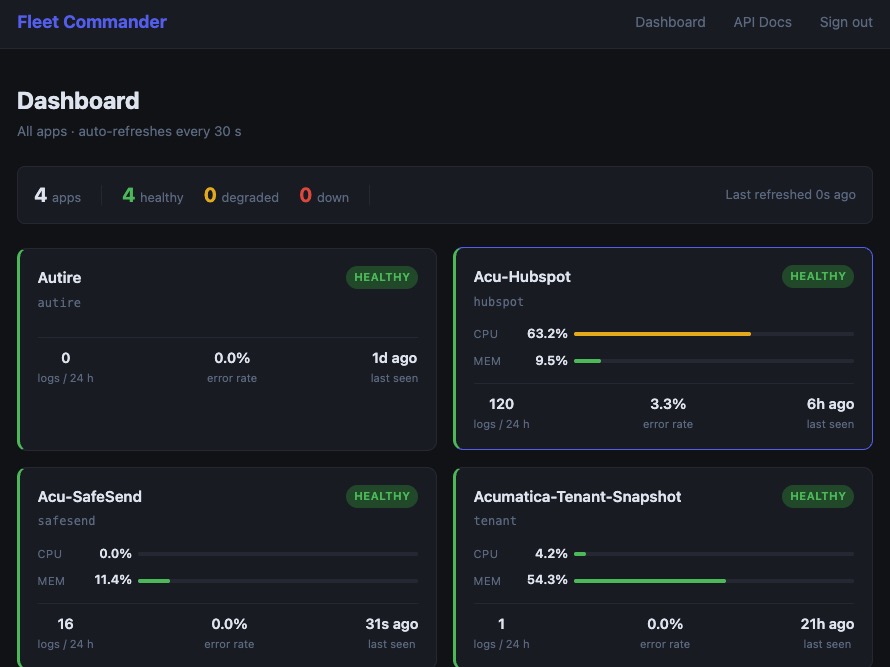
The Architecture:
- The Hub: A lightweight Docker container running FastAPI.
- The Integration: Each isolated app pushes logs and metrics to its unique endpoint (with unique keys).
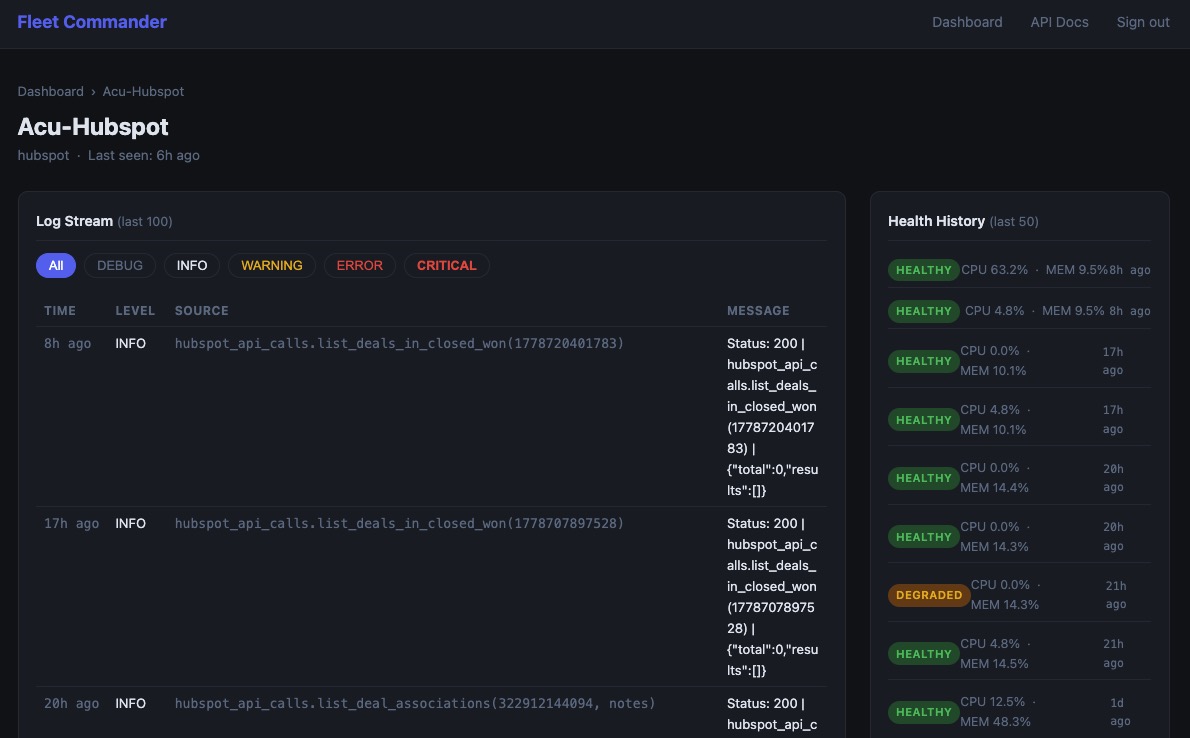
- The Dashboard: A simple dashboard shows error rate, uptime, and health metrics. Number of logs / 24 hours (this tells me if the app is actively being used). I can click on each app to see more detailed logs, monitor usage, etc. Are there any signs of life?
- The Robot Brain: 4B Gemma model. This is a lightweight LLM that runs right in a container on my VPS — completely private, no external API calls. It monitors the logs. When anything seems out of the ordinary it sends me a message. Not a huge resource tax. Currently, it is eating up 800 MB of RAM. I'd like to cut this in half.
Sure I could use regex patterns or static thresholds to solve this problem. But, if I don't mention AI 3x / hour, I could lose my job.
The "Why": Context Over Regex
Truthfully, it is because some of these apps will have routine errors — a user forgot a required field, credentials were updated, etc. As I work with the model, I can update its context to learn what is within the "range of normal." I have a local LLM that understands context.
I have multiple programming languages to monitor, and different apps to keep in my context window. If the burden of task switching lowers slightly, the effort will be worth it. Freed up attention means I can build more.

I am protecting the valuable resource of attention. With attention comes focus. With focus, I can bring creative solutions. Creative solutions lead to the maximal point of leverage.

{kind=link}